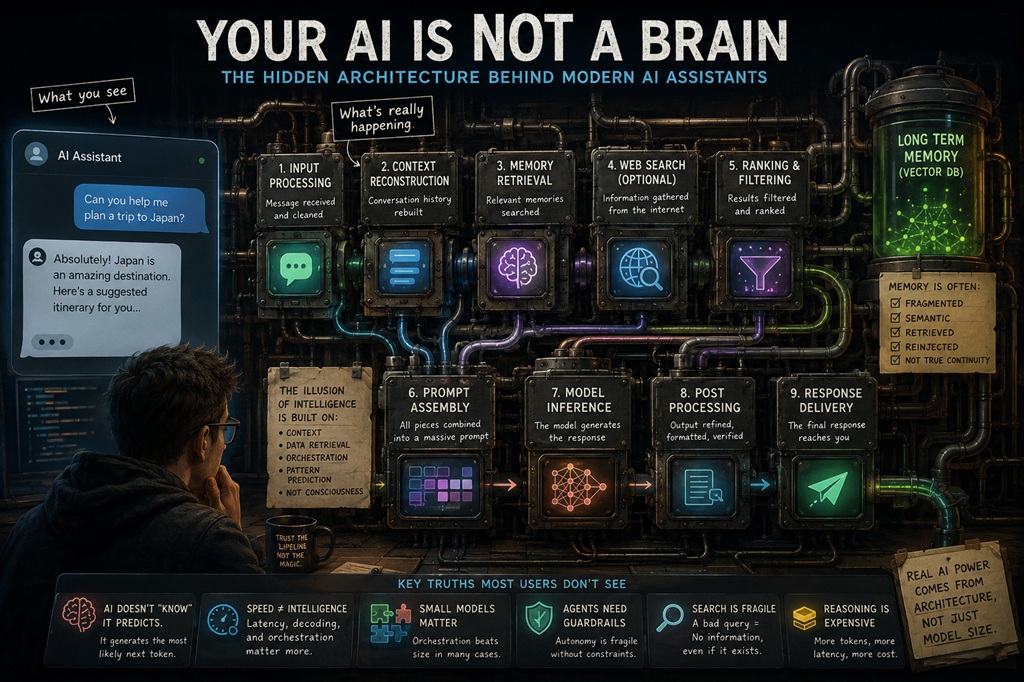
When most people interact with an AI assistant, they imagine a single intelligent entity thinking continuously in real time.
That is not what usually happens.
Behind the friendly interface, modern AI systems are often a collection of pipelines, orchestrators, ranking systems, memory injectors, validators, search engines, caches, and multiple specialized models working together behind the scenes.
The “AI” users interact with is frequently the final layer of a much larger machine.
And understanding this changes everything.
- The illusion of continuous intelligence
- AI memory is often an elegant illusion
- Bigger models are not always better
- The real problem with local AI is not the model
- AI image generation often spends more time decoding than “thinking”
- Autonomous AI agents are less autonomous than they appear
- Humans are extremely vulnerable to AI illusions
- Internet search in AI systems is more fragile than most people realize
- Reasoning models are expensive in hidden ways
- The future of AI is probably architectural
The illusion of continuous intelligence
Most users imagine an AI assistant as something similar to a digital brain:
- it remembers,
- it reasons,
- it understands context,
- it continuously learns during conversation.
In reality, many systems work more like this:
- The user sends a message.
- The system rebuilds the conversation context.
- Relevant memories are retrieved from storage.
- Internet search may be triggered.
- Results are filtered and ranked.
- Instructions and personality prompts are reinjected.
- A final massive prompt is assembled.
- Only then does the language model generate a response.
What appears to be a single intelligence is often an orchestration layer coordinating multiple independent processes.
This is one of the least understood aspects of modern AI systems.
AI memory is often an elegant illusion
Users frequently say: “The AI remembers me.”
Sometimes it does.
But often, what looks like memory is actually retrieval.
The system:
- stores conversation fragments,
- extracts keywords and embeddings,
- searches for semantically related information,
- and reinjects selected memories back into the prompt.
In other words, many AI assistants “remember” the same way an actor remembers a script:
someone keeps handing them notes offstage.
This approach works surprisingly well, but it also explains why memory failures happen so often:
- details disappear,
- identities become inconsistent,
- old context gets overwritten,
- reasoning models consume too much context space,
- and conversations drift.
Persistent, coherent long-term memory remains one of the hardest open problems in AI engineering.
Bigger models are not always better
One of the most important lessons emerging from real-world AI deployment is this:
Large models are not automatically the most useful models.
In many practical systems, better results come from combining:
- a small fast model,
- a specialized reasoning or validation model,
- and a larger model only when truly necessary.
Why?
Because the real bottlenecks are often:
- latency,
- GPU memory,
- token consumption,
- orchestration overhead,
- cost,
- and system stability.
A fast 4B model coordinating a larger architecture can sometimes outperform a massive standalone model in responsiveness and reliability.
This is especially important for local AI systems running on consumer hardware.
The real problem with local AI is not the model
Most users think the hard part is downloading the model.
It is not.
The real challenge is everything around it:
- CUDA,
- ROCm,
- Vulkan,
- Python environments,
- incompatible libraries,
- GPU drivers,
- tokenizers,
- dependency conflicts,
- memory allocation,
- VAE decoding,
- and operating system inconsistencies.
Modern AI software stacks are extremely fragile.
One mismatched library version can break an entire system.
This is why many developers eventually resort to containers and isolated environments:
not because they are elegant,
but because they reduce chaos.
AI image generation often spends more time decoding than “thinking”
Image generation systems create another illusion.
Users often assume the GPU is “thinking” slowly.
But in many pipelines, especially on consumer hardware, the diffusion process itself is not the main bottleneck.
The real problem is frequently:
- VAE decoding,
- VRAM pressure,
- CPU fallback operations,
- memory transfer overhead,
- or image upscaling.
This is why users sometimes see:
- low GPU utilization,
- massive delays,
- or unstable performance.
The visible generation is only one part of the pipeline.
Autonomous AI agents are less autonomous than they appear
The internet is currently flooded with “fully autonomous AI agent” demos.
Many are impressive.
But behind the scenes, most rely heavily on:
- rigid workflows,
- predefined toolchains,
- retry loops,
- validation systems,
- human supervision,
- hardcoded safety layers,
- and carefully engineered prompts.
Generating code is not the hardest problem.
The hardest problems are:
- deciding when to stop,
- avoiding destructive actions,
- validating outputs,
- managing memory,
- maintaining consistency,
- and recovering from failure states.
True autonomy is far more difficult than generating convincing demos.
Humans are extremely vulnerable to AI illusions
Modern language models trigger powerful psychological responses.
Users naturally:
- attribute intentions,
- perceive emotions,
- infer personality,
- and project consciousness onto text generation systems.
Even when the system is simply predicting statistically likely tokens.
And yet, the social simulation works.
Humans react to narrative consistency more than to actual consciousness.
This creates one of the strangest technological moments in modern history:
machines do not need to be conscious to become socially influential.
Internet search in AI systems is more fragile than most people realize
Users often assume AI assistants simply “search the web.”
But web augmentation is a complex pipeline involving:
- deciding whether search is necessary,
- generating queries,
- selecting sources,
- filtering spam,
- ranking relevance,
- merging results,
- and injecting the information back into the model context.
A poorly generated query can completely fail even when the correct information exists online.
This is why intelligent routing and semantic scoring systems are becoming increasingly important in advanced AI architectures.
Reasoning models are expensive in hidden ways
Reasoning-focused models are extremely impressive.
But they also consume enormous resources:
- more tokens,
- more context space,
- more latency,
- and more compute time.
For consumer AI systems and local deployments, this creates a difficult balance:
how much reasoning is actually useful before responsiveness collapses?
Many future AI systems will likely rely on layered architectures:
- small reactive models,
- specialized validators,
- targeted reasoning passes,
- and selective escalation to larger models only when necessary.
The future may belong less to giant monolithic models,
and more to intelligent orchestration.
The future of AI is probably architectural
The next major breakthroughs in AI may not come purely from larger models.
They may come from:
- better orchestration,
- persistent memory systems,
- adaptive routing,
- multimodal integration,
- local/cloud hybrid architectures,
- and efficient collaboration between specialized models.
The era of the “single giant AI brain” may eventually give way to ecosystems of smaller, cooperative intelligences.
Ironically, the closer AI systems get to biological intelligence,
the less they resemble a single isolated mind.
And more they resemble societies.